
一、字符串(str)数据类型讲解
1.字符串是什么
字符串是一种有序且不可变的序列类型,因此也支持序列类型的各种操作,例如索引和切片。
2.转义字符的概念
python当中,定义一个字符串可以使用单引号,比如s = ‘abcd’,那么如何在这样的字符串里写一个单引号呢?比如你需要定义一个字符串 it’s a book
s = 'it's a book'
如果你是这样实现的,编辑器就会报错,因为这个字符串是用单引号括起来的,可是中间又出现一个单引号,到底哪两个单引号构成一个字符串呢?这里面就出现了歧义,而计算机最怕的就是歧义,为了解决歧义,我们引入了转义字符的概念。
一些特殊字符无法直接在字符串里表示,这时就必须使用转义字符(一个\加上特定的字符), 比如换行(\n)、 单引号(')、双引号(")等等,转义字符不是python这门语言所独有的,这是一个计算机专业词汇。
s = 'it\'s a book' #单引号的你学会了,双引号的也是相同的道理,s = "使用\"创建字符串"
s = "使用\\创建字符串"#如果要在字符串里使用\,则需要写成 \\
s = "换行符是\\n" #换行符是\n
#符号\除了用来定义转义字符,还可以用来做续行符,Python官方建议每行代码的长度不要超过80个字符,对于一行中较长的代码,可以通过续行符进行换行(编辑器里看上去是换行了,但程序不认为你换行了)
比如我要输出 "123"
print("1
2
3")
#如上写法会报错
print("1/
2/
3")
#这样写才是对的,注意如果缩进的话,会被当空格输出
转义字符汇总说明
| 转义字符 | 描述 | 实例 |
|---|---|---|
| \n | 换行 | print("\n") |
| (在行尾时)\ | 续行符(输入后可以到下一行输入) | print("line1 \ ... line2 \ ... line3") line1 line2 line3 |
| \\ | 反斜杠符号 | print("\\") 输出\ |
| \’ | 单引号 | print('\'') 输出' |
| \" | 双引号 | print("\"") " |
| \a | 响铃 | print("\a") 输出执行后电脑有响声(我的电脑不响)。 |
| \b | 退格(Backspace) | print("Hello \b World!") Hello World!,删除一个字符。 |
| \000 | 空 | print("\000") |
| \v | 纵向制表符 | print("Hello \v World!") Hello World! >>> |
| \t | 横向制表符 | print("Hello \t World!") Hello World! >>> |
| \r | 回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 | print('google runoob taobao\r123456') 123456 runoob taobao |
| \f | 换页 | print("Hello \f World!") Hello World! |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | print("\110\145\154\154\157\40\127\157\162\154\144\41") Hello World! |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") Hello World! |
| \other | 其它的字符以普通格式输出 |
3.创建字符串的方式
创建字符串,或者说字符串的表达方式,有三种:
-
普通字符串:指使用单引号或双引号括起来的字符串
-
原始字符串:指使用r或R开头后,用单引号或双引号括起来的字符串,r/R是raw的缩写,表示字符串为原始的含义,无需转义
-
长字符串:指使用三个单引号或三个双引号括起来的字符串,字符串内可以包含换行、缩进等特殊字符
第一类:普通字符串
#第一类为普通字符串:指使用单引号或双引号括起来的字符串,一般习惯上我们会用单引号,除非文本内容本身就有单引号,才会用双引号
str_1 = '单引号'
str_2 = "双引号"
str_3 ="混合'引号" #结果为 混合'引号,字符串本身包括单引号时,可以使用双引号括起来,不需要转义
str_4 ='混合"引号' #结果为 混合"引号,字符串本身包括双引号时,可以使用单引号括起来,不需要转义
第二类:原始字符串
#第二类为原始字符串:指使用r开头后,用单引号或双引号括起来的字符串,r是raw的缩写,表示字符串为原始含义,无需转义
#如果我要显示 hello \n world 这11个字母+1个反斜杠+两个空格,直接写 str="hello \n world",得到的是两行字符,第一行是hello+空格,第二行是world+空格。这显然不符合我们的要求
#当然,你可以通过转义字符来达到要求:str="hello \\n world",但如果字符里面有特别多需要转义的字符,会特别麻烦
#所以我们可以用原始字符串(raw string)的写法,可以得到 hello \n world ,\n表示的不再是换行符,而是\和n两个字符:
str1 = r'hello \n world'
str2 = r"hello \n world"
#经常在open()函数打开Windows文件的时候会使用raw字符串。例如下面三种方式:
open('d:\new\test.txt') # (1)
open('d:\\new\\test.txt') # (2)
open(r'd:\new\test.txt') # (3)
#(1)中解释字符串的时候,发现里面有\n和\t,它们会分别解释为换行符和制表符,这显然不可能是想要打开的文件路径。所以,在(2)中,使用反斜线将反斜线自身进行了转义。而(3)中使用r声明这是一个raw字符串,里面的转义字符不会进行转义,只会作为普通字符,所以这里的\表示的是路径的分隔符号。
#显然用原始字符串的方式,比繁琐的转义要简单直观
#注意,raw字符串不能以反斜线结尾,除非对其转义。例如r'abc\ndef\'是错误语法,但r'abc\ndef\\'是正确的语法,它表示后面有两个反斜线字符。
>>> r'abc\nd\a\\'
'abc\\nd\\a\\\\'
>>> print(r'abc\nd\a\\')
abc\nd\a\\
>>> r'abc\nd\a\'
File "<stdin>", line 1
r'abc\nd\a\'
^
SyntaxError: EOL while scanning string literal
第三类:长字符串
#第三类为长字符串:指使用三单引号或三双引号括起来的字符串
#为了避免转义的麻烦,我们之前说可以用原始字符串的方式,但如果字符串中也有单引号或双引号,就要用长字符串方式
#字符串中可以包含换行符(即允许一个字符串跨多行)、制表符、引号以及其他特殊字符。
#当要对一串复杂文本进行处理时,优先使用三引号。
str_1 = '''三单引号'''
str_2 = """三双引号"""
str_3 = """混合'''三引号""" #字符串本身包括三单引号时,可以使用三双引号括起来,不需要转义
str_4 = '''混合"""三引号''' #字符串本身包括三双引号时,可以使用三单引号括起来,不需要转义
#示例1:
str_demo0 ='''这是多行字符串
的一个演示demo,不管是\n换行
还是\t横向制表符
都可以生效,不会被转义
文本中经常见到"或',但是很少见到三引号
用三引号,可以避免字符串范围识别错误
一个典型的用例是,当你需要一块HTML或者SQL时,这时用字符串组合,特殊字符串转义将会非常的繁琐,用三引号会很方便
如果想把开头的三引号放在变量名下面,那么要在=后面加上一个反斜杠\表示续行,否则报错
可以理解为告诉程序,我不想在这行继续写了,在下行开始写,请程序不要认为我是换行了
当然,还可以用括号,等号后面左括号,下一行开始写三引号和文本,最后的三引号后面加个右括号
但是用括号的时候,要保证字符串里面不要出现括号
'''
#示例2:通过反斜杠\来实现换行续写,下面demo1和demo2的结果一致。
#如果不加这个反斜杠就换行,如demo3,python会把这个换行算在文本中,相比1和2,demo3在文字部分前后各多了一个空行
#demo4会报错。
str_demo1 =\
'''文字部分'''
str_demo2 =\
'''\
文字部分\
'''
str_demo3 =\
'''
文字部分
'''
str_demo4 =
'''
文字部分
'''
#示例3:使用括号来实现换行再输入,demo5的结果和上面的demo1或demo2一致。
str_demo5 =(
'''文字部分'''
)
#使用()括号时可以跨行书写,这是python语法中各种括号类型的特性,包括后面学到的[]和{}都是支持跨行书写的。
'''
三引号不仅可以用来创建长字符串,还可以用来做注释,放在自定义函数的下面,自定义类的下面,模块文件的前面等位置(后续遇到时会讲)。三引号又叫块注释符,用来注释一段代码。这表示这段被包围的代码解释为字符串,但因为没有赋值给变量,所以编译器会直接丢弃,不进行编译(这就是注释的特性)。
'''
4.索引的概念
python没有单字符类型,单字符在Python中也是一个字符串类型。字符串是字符的有序集合,有序意味着每个字符都有自己的位置,专业术语叫索引,比如字符串’python’,这个字符串的第6个字符是n,这个就是索引,但与我们熟悉的计数方式不同,编程世界的索引都是从0开始,因此n在字符串python中的索引是5而不是6。
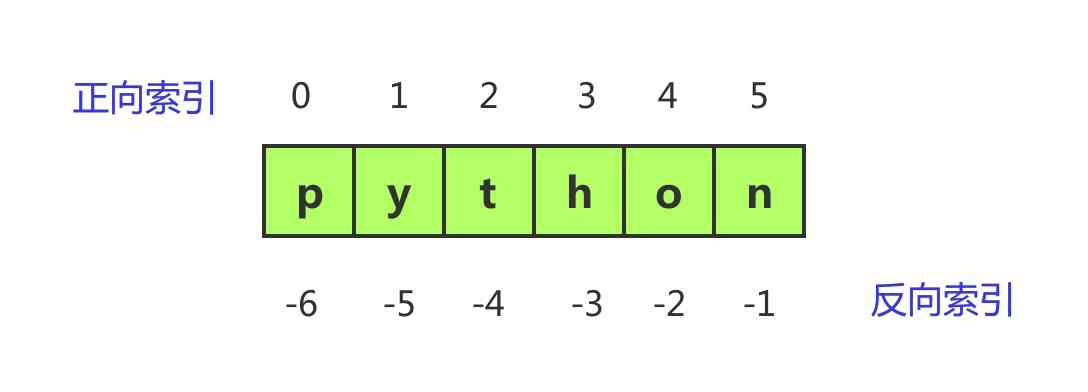
Python还支持反向索引,字符n的索引不仅可以是5,还可以是-1,正向索引的最小值是0,反向索引的最大值是-1,-1代表最后一个字符,0代表第一个字符,这里不要混淆。
Python可以通过索引来访问字符串,方式是使用一对中括号[],在其中填写索引。但要注意,如果索引超出了范围,就会引发IndexError,这是初学者非常容易遇到的错误。
a='python'[5] #输出p
b='python'[-1] #输出n
c='python'[-6] #输出p
d='python'[5] #输出n
e='python'[10]#该字符串最大索引是5,索引10会超出范围越界,报错如下
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
Python 中的字符串不能被修改
另外,Python 中的字符串不能被修改,它是不可变数据类型。因此,向字符串的某个索引位置赋值会产生异常:
'python'[0]='Z'
TypeError: 'str' object does not support item assignment
5.切片的概念
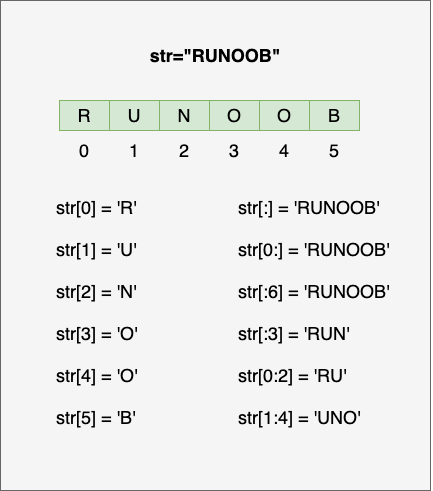
通过[start :end] 截取字符串中的一部分,遵循左闭右开原则,即str[0:2] 是不包含索引[2]的值(第 3 个字符),也就是说索引为end的元素不会被截取。
字符串的切片支持索引越界、指定切片间隔等特殊用法。字符串切片之后,得到的结果仍然还是字符串,不会变成列表。
a='python'[1:3] #表示[索引1,索引3)这个范围内的字符,范围左闭右开,结果是"yt"
b='python'[:3] #表示从索引0开始到索引3,结果是"pyt"。指定结束位置,不指定开始位置,意味着从第一个字符开始
b='python'[1:] #表示从索引1开始到索引结束,结果是"ython"。指定开始位置,不指定结束位置,意味着到末尾最后一个字符
d='python'[:] #表示从索引开始到索引结束,结果是"python",冒号表示进行切片,如果左右两侧索引都不写,就默认是最开始到最末尾
e='python'[::] #表示从索引开始到索引结束,结果是"python",[::]和[:]的结果一样,建议只用[:],详见下面切片间隔讲解
f='python'[0:20] #结果为"python",切片操作允许索引越界,程序会自动判断边界
#关于切片间隔
a='123456789'[::2] #结果是"13579"
#[]操作符内有两个:, 这两个要分开理解:
#对于第一个,我们将其理解为设置索引,:左右两侧都没有明确写明索引值,这就相当于既没有指定开始索引,也没有指定结束索引,因此等价于开始索引从0开始,结束索引就是字符串的末尾。
#对于第二个: 的作用是设置切片的间隔,后面跟着数字2,表示每隔2个索引做一次切片处理,这样就最终得到了'13579'。
b='123456789'[::] #结果是"123456789",第一个冒号表示 0:末尾,第二个冒号表示设置间隔,但是没有写间隔的数值,不写间隔值时,默认间隔值为1
#如果间隔不需要处理(默认为1),建议直接用[:]即可,虽然[::]的结果一样,但显得多此一举
c='123456789'[::-1]#结果是"987654321",切片间隔可以是负数,表示反向间隔,常用[::-1]实现字符串翻转
#我们经常用切片间隔,来取奇数位置上的字符和偶数位置上的字符
str[::2] # 取奇数位
str[1::2] # 取偶数位
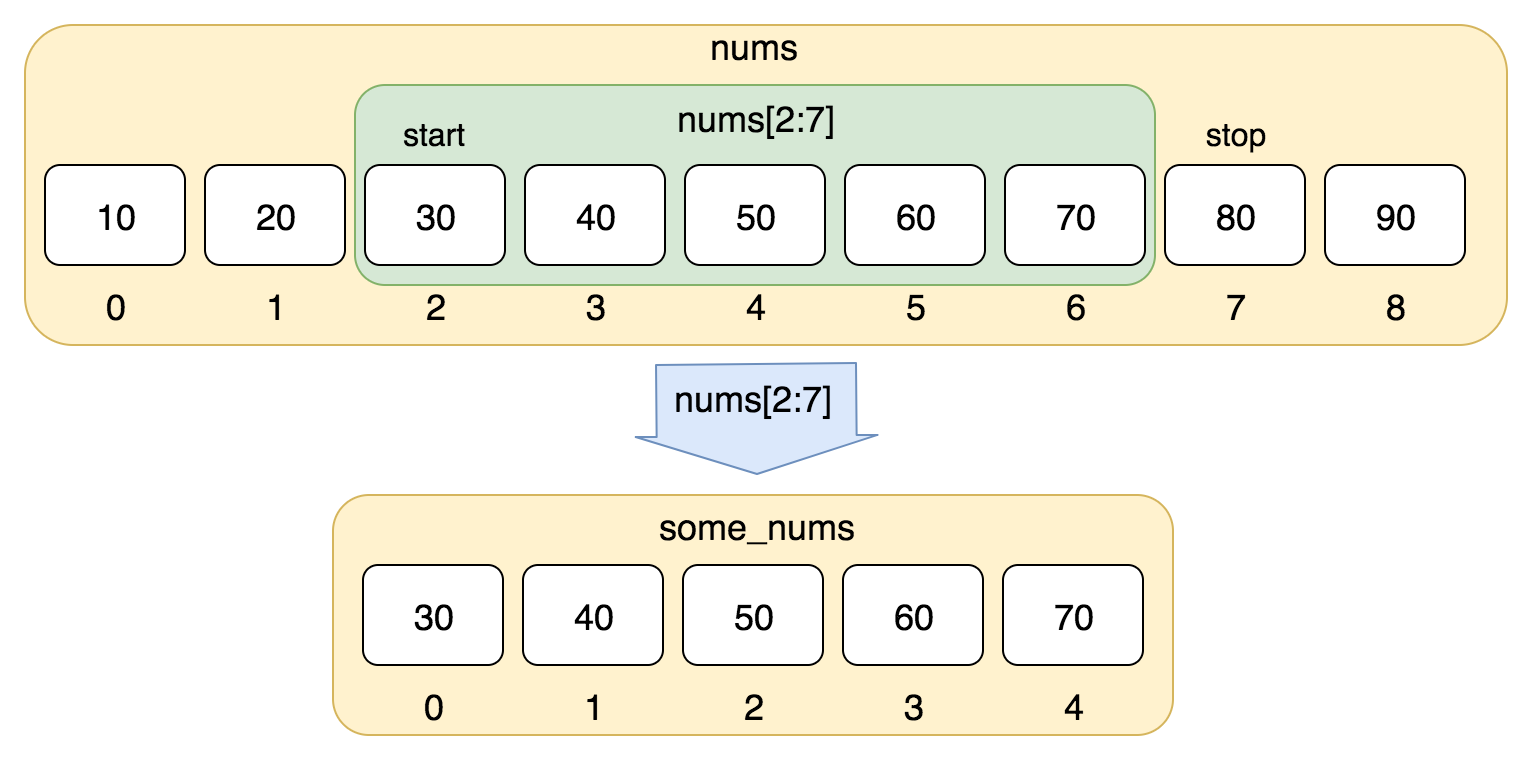
也可以这么理解切片:将索引视作指向字符之间,第一个字符的左侧标为0,最后一个字符的右侧标
为n ,其中n 是字符串长度。例如:

6.字符串运算符
下表中,变量 a 值为字符串 “Hello”,变量b为字符串 “Python”:
| 操作 符 | 描述 | 实例 |
|---|---|---|
| + | 字符串无缝连接,中间没有空格或逗号等间隔符号。字符串连接,如"abc" "def"或"abc" + "def"是等价的,都是"abcdef", |
a + b 输出结果: HelloPython |
| * | 重复输出字符串,如"c" * 3得到"ccc",再比如我们可以用print(“-” * 20) 输出分割线 |
a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符,如果字符串中包含给定的字符返回 True(不要用or来处理,要用in) (因为python中的字符串是一种序列类型,所以可以使用 in来测试字符串中是否包含某个字符或子串) |
‘He’ in a 输出结果 True;‘Ho’ in a 输出结果 False |
| not in | 成员运算符, 如果字符串中不包含给定的字符返回 True(不要用or来处理,要用in) | ‘M’ not in a 输出结果 True |
| r/R | 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' ) |
| % | 格式字符串 | 请看格式化字符串内容 |
当比较一个字符串和一个只包含1个字符串的元组时,需要注意in的判定。
'monday' in ('I love monday')
结果是真,就像我们在比较两个字符串一样(原因是 单个元组 应该加逗号结束,这里没有逗号,并不是元组)
但是如果我通过在元组中添加另一个元素来更改表达式。
'monday' in ('I love monday', 'I love monday too')
它返回False,因为元组中两个元素,没有哪个元素是'monday'。
返回True的情况:print('I love monday' in ('I love monday', 'I love monday too'))
7.字符串格式化
Python 有多种方式支持格式化字符串的输出,比如 %格式化(python全版本支持,能不用就不用,可阅读性差)、.format方法格式化(python2.6开始支持,一般不建议用)、format()函数格式化(和字符串的format方法异曲同工)、f-string格式化(Python3.6开始支持,最推荐)
1. f-string 格式化
f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去。这种技术称之为字面量格式化字符串。{}中的表达式,可以是字符,可以是计算式,可以是字典或列表等等。
name='python'
sport="football"
print(f'Hello,{name},I like {sport}.)
#输出: Hello,I like football.
print(f'结果是{1+2}') #输出:结果是3
a = {'name': '我的博客', 'url': 'blog.ziyong.site'}
b = '{w["name"]}: {w["url"]}'#这是一种字典数据结构,后续会学习到
输出b的结果是 '我的博客: blog.ziyong.site'
在 Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果:
x = 1
print(f'{x+1=}') # 在Python3.8及其以上,输出为 x+1=2
2. format()字符串方法格式化
.format方法 格式化字符串,实际上是字符串的一个方法(后面讲什么是方法,暂时理解为一种功能),字符串中希望被替换的内容,用大括号包裹起来(称作占位符,大括号中的内容既可以是索引值,也可以是关键字),在format方法的参数里,你需要设置替换的内容,比如在例子中,设置color = ‘蓝色’, 那么字符串里,所有的{color}都会被替换成蓝色。
string = "I like {color}".format(color='red')
print(string) #I like red
string = "我喜欢{color},{color}就是我".format(color='蓝色')
print(string) #我喜欢蓝色,蓝色就是我
string = "{course}考了90分,{name}感觉失望"
string = string.format(course="语文", name="蓝色")
print(string) #语文考了90分,蓝色感觉失望
使用format()来格式化字符串时,在字符串中使用{}作为占位符,占位符的内容将引用format()中的参数进行替换。可以是位置参数、命名参数或者兼而有之(学完函数一章,就会明白这些词的含义),暂且先看示例:
# 位置参数,根据索引位置一一对应
>>> template = '{0}, {1} and {2}.format('A','B','C')'
'A, B and C'
#上面这一句可以分成两句写,更加直观,本质上就是用一个变量template指代了字符串:
template = '{0}, {1} and {2}'
template.format('A','B','C')
# 命名参数,左边参数名,中间等号,右边是要赋予的值
>>> template = '{name1}, {name2} and {name3}'
>>> template.format(name1='A', name2='B', name3='C')
'A, B and C'
#注意,string = "我喜欢{color},{color}就是我".format('蓝色','蓝色')会报错,
# 混合使用位置参数、命名参数
>>> template = '{name1}, {0} and {name3}'
>>> template.format("A", name1='B', name3='C')
'A, B and C'
因为字符串中的占位符是直接引用format中的参数属性的,在占位符处可以进行索引取值、方法调用等操作。例如:
>>> import sys
>>> 'My {config[name]} OS is {sys.platform}'.format(config={'name':'loptop'},sys=sys)
'My loptop OS is win32'
>>> 'My {config[name]} OS is {sys.platform}'.format(sys=sys,config={'name':'loptop'})
'My loptop OS is win32'
>>> 'My {1[name]} OS is {0.platform}'.format(sys,{"name":"laptop"})
'My laptop OS is win32'
但是,在占位符使用索引或切片时,不能使用负数,但可以将负数索引或负数切片放在format的参数中。
>>> s = "hello"
>>> 'first={0[0]}, last={0[4]}'.format(s)
'first=h, last=o'
# 下面是错的
>>> 'first={0[0]}, last={0[-1]}'.format(s)
# 下面是正确的
>>> 'first={0[0]}, last={1}'.format(s, s[-1])
'first=h, last=o'
format()作为函数,它也能进行参数解包,然后提供给占位符。
>>> s=['a','b','c']
>>> '{0}, {1} and {2}'.format(*s)
'a, b and c'
在占位符后面加上冒号和数值可以表示占用字符宽度。
>>> '{0:10} = {1:10}'.format('abc','def') #字符默认左对齐
'abc = def '
>>> '{0:10} = {1:10}'.format('abc',123) #数值默认右对齐
'abc = 123'
>>> '{0:10} = {1:10}'.format('abc',123.456)
'abc = 123.456'
使用<表示左对齐,>表示右对齐,^表示居中对齐,并且可以使用0来填充空格。
>>> '{0:>10} = {1:>10}'.format('abc','def')
' abc = def'
>>> '{0:>10} = {1:<10}'.format('abc','def')
' abc = def '
>>> '{0:^10} = {1:^10}'.format('abc','def')
' abc = def '
>>> '{0:10} , {1:<06}'.format('abc','def')
'abc , def000'
>>> '{0:10} , {1:>06}'.format('abc','def')
'abc , 000def'
>>> '{0:10} , {1:^06}'.format('abc','def')
'abc , 0def00'
可以指定e、f、g类型的浮点数,默认采用g浮点数格式化。例如:
>>> '{0:f}, {1:.2f}, {2:06.2f}'.format(3.14159, 3.14159, 3.14159)
#f前面的数值表示的是保留的小数位数,输出结果为:
'3.141590, 3.14, 003.14'
:.2f表示保留两位小数,:06.2f表示最大长度位6字符,左边使用0填充而不是字符串,保留2位小数。
甚至,可以从format()中指定小数位数。
>>> '{0:.{1}f}'.format(1/3, 4)
'0.3333'
3.format()内置函数格式化
除了字符串方法format(),python还提供了一个快速格式化单个字符串目标的内置函数format(),用法和字符串的.format()方法差不多,一般很少用,不过多介绍。
用法示例:
>>> '{0:.2f}'.format(1.2345) #.format方法
'1.23'
>>> format(1.2345, '.2f')#.format函数
'1.23'
>>> '%.2f' % 1.2345#%占位符格式化字符串
'1.23'
4.%占位符格式化字符串
**%**格式化字符串,类似于C语言中的printf风格,在字符串中使用%作为占位符。python提供了很多字符串格式化符号和格式化操作符辅助指令,用于实现各种各样的字符串格式化。但我并不推荐你用这种方法,因为这样写出来的代码可阅读性较差。
name='python'
print("Hello,%s" % name)
#输出时,会将name变量的值'python'替换到 %s 的位置,结果是 Hello,python
#注意,因为变量name的值'python'是个字符串,所以%后面跟的是s,如果是整数,要用%d,不同情况要用不同的字符串格式化符号
print("Hello,%s,%s" % (name,'fine')) #结果是 Hello,python,fine
#字符串中使用%作为占位符,字符串和替换目标之间也使用%分隔,且替换部分可以有多个(使用括号包围),替换部分可以使用变量。
print("%(name1)s with %(name2)s" % {"name1":"A", "name2":"B"}) #结果是 A with B
#替换目标还可以使用字典,这时在字符串中的%占位符可以用key的方式来引用:
python字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %c | 格式化字符及其ASCII码 |
| %x | 格式化无符号十六进制数,若使用%#x,格式化为有符号十六进制数,十六进制的符号是0x(前者数字0,后者字母x) |
| %X | 格式化无符号十六进制数(大写) |
| %o | 格式化无符号八进制数,若使用%#o,格式化为有符号八进制数,八进制的符号是0o(前者数字0,后者字母o) |
| %u | 格式化无符号整型 |
| %p | 用十六进制数格式化变量的地址 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写,意思是说,如果值是一个整数,当小于等于六位数的时候,输出的是一个整数,当该整数是七位数及以上的时候,输出的是科学计数法;如果值是一个浮点数,%g会去掉多余的0,至多保留六位有效数字。 |
| %G | %f 和 %E 的简写 |
num=10
print('十六进制:%x' % num) #使用%x将十进制num格式化为无符号十六进制
十六进制:a
print('十六进制:%#x' % num) #使用%#x将十进制num格式化为有符号十六进制
十六进制:0xa
print('十六进制:%X' % num) #使用%X将十进制num格式化为无符号十六进制(字母大写)
十六进制:A
print('十六进制:%#X' % num) #使用%#X将十进制num格式化为有符号十六进制(字母大写)
十六进制:0xA
print('八进制:%o' % num) #使用%o将十进制num格式化为无符号八进制
八进制:12
print('八进制:%#o' % num) #使用%#o将十进制num格式化为有符号八进制
八进制:0o12
print('二进制:', bin(num)) #使用bin将十进制num格式化为有符号二进制
二进制: 0b1010
上面使用格式化符号进行进制转换中,多加入了一个#号,目的是在转换结果头部显示当前进制类型,0x、ob、0o,如不需要,可将#号去除,如下
a=100000
print("%g"%(a))
#输出为100000
a=10000000
print("%g"%(a))
#输出为1e+07
a=1000000
print("%g"%(a))
#输出为1e+06
a=100000.0
print("%g"%(a))
#输出为100000
print("%f"%(a))
#输出为100000.000000
a=100000.1
print("%g"%(a))
#输出为100000
a=1.0
print("%g"%(a))
#输出为1
a=1.1
print("%g"%(a))
#输出为1.1
%g 用于打印数据时,会去掉多余的零,至多保留六位有效数字。
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%‘输出一个单一的’%’,相当于转义 |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
8.字符串相关的函数方法
在python中,操作字符串的方式有多种,除了上面提到的字符串运算符和字符串格式化,还有字符串能用的方法(或者暂时理解为函数/一种功能)
- 字符串是一个序列,且是不可变序列,所以序列的通用操作和不可变序列的操作都能应用在字符串上
- zi’fu’ir对象自身实现了很多方法,比如大小写转换、子串搜索、截断等等
- 可以参考:https://www.cnblogs.com/f-ck-need-u/p/9127699.html
| 序号 | 方法是字符串这种数据类型的功能函数,使用形式如: 字符串.方法名(参数) |
|---|---|
| 转换大小写类 | |
| upper() 转换字符串中的小写字母为大写 | |
| lower() 转换字符串中所有大写字符为小写 | |
| title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写,要注意非字母后的第一个字母将转换为大写字母:b2b2bb2会转换为B2B2Bb2 | |
| swapcase() 将字符串中大写转换为小写,小写转换为大写 | |
| capitalize() 将字符串的第一个字符转换为大写,注意开头是非字母情况,如 ‘学习pYTHOn’.captlize()的结果是 ‘学习python’ | |
| 判断类 | |
| isdigit() 如果字符串只包含数字(正整数,也就是[0-9]十个元素)则返回 True 否则返回 False. | |
| isnumeric() 如果字符串中只包含数字字符( 数字,全角数字,罗马数字,汉字数字,指数类似 ² 与分数类似 ½ 也属于数字),则返回 True,否则返回 False | |
| isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false | |
| isalnum() 如果字符串至少有一个字符并且所有字符都是数字或字母则返回 True,否则返回 False,不区分是整数、浮点数还是大写、小写。实测发现, 如果是汉字,也会返回True。 | |
| isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False | |
| islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是小写,则返回 True,否则返回 False | |
| isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是大写,则返回 True,否则返回 False | |
| isspace() 如果字符串中只包含空白,则返回 True,否则返回 False。空白字符包括空格、制表符(\t)、换行(\n)、回车(\r),必须注意,空串会返回False,print(“”.isspace())的结果是False。 | |
| istitle() 如果字符串是标题化的(见 title()),则返回 True,否则返回 False。但如果字符串中没有字母,则会报False。‘1X23Xasd’.istitle()的结果也是True,因为数字分隔开了X和Xasd,相当于两个单词。 | |
| startswith(substr, beg=0,end=len(string)) 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查 | |
| endswith(suffix, beg=0, end=len(string)) 检查字符串是否以子字符串suffix 结束,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查 | |
| 修改类 | |
| join(seq) 以指定字符串作为分隔符,将序列中所有的元素(的字符串表示)合并为一个新的字符串,序列中的元素只能是str类型,如果是int型会报错。另外,官方原文说的不是序列,是可迭代对象,序列是可迭代对象的一种而已。当连接对象是字符串、元组、列表、字典时,会按顺序连接,当连接对象是set集合时,会随机打乱顺序连接。此处可以看join转为字符串部分内容。 | |
| replace(old, new , max]) 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 | |
| maketrans(intab,outtab,delchars) 创建字符映射的转换表table供translate()使用,实现批量替换字符串内容,Python3.4开始,该函数已被内建函数: str.maketrans() 、bytes.maketrans()、bytearray.maketrans()、取代。 | |
| translate(table) 根据 table 给出的映射关系,批量替换 string 中的字符 | |
| lstrip([chars]) 截掉字符串左边的空格或指定字符。从左往右删,一旦字符不是目标字符,停止操作。 | |
| rstrip(([chars])) 截掉字符串末尾的空格或指定字符。一旦字符不是目标字符,停止操作 | |
| strip(chars]) 在字符串上执行 lstrip()和 rstrip(),print(‘6688668866’.strip(‘66’))的结果是886688 | |
| split(str=“”, num=string.count(str)) split() 通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。num – 分割次数。默认为 -1, 即分隔所有。注意,print(‘1aa2’.split(‘a’))的结果是 [‘1’, ‘’, ‘2’],以a为分隔符切分时,程序认为两个a之间有一个空字符串,因此产生一个空字符串,这是正确的,否则以aa为分隔符的时候,和以a为分隔符就乱套了。 | |
| partition()用来根据指定的分隔符将字符串进行分割。如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。 | |
| splitlines(keepends]) 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 | |
| expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 | |
| 填充类 | |
| zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0。zfill(width) 作用同 rjust(width,“0”) | |
| ljust(width, fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 | |
| rjust(width, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 | |
| center(width, fillchar)返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。要注意,filllchar只能是单个字符,默认是空格。只需要补一个(或者说需要补奇数个)的情况:字符串中是奇数个字符,优先往右补,字符串中是偶数个字符,优先往左补。 | |
| format()从Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。基本语法是通过 {} 和 : 来代替以前的 % 。format 函数可以接受不限个参数,位置可以不按顺序。 | |
| 查找类 | |
| min(str) 返回字符串 str 中最小的字母。返回字符串中最小的字符,注意该函数不只判断字母,会判断字符串中的所有字符,按照字符在 unicode 中的编码值来决定大小:同一个字符,大写比小写要小,数字比字母要小,符号比字母要大。常见的ascaii编码:0-9<A-Z<a~z | |
| max(str) 返回字符串 str 中最大的字母。 | |
| len(string) 返回字符串长度 | |
| count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 | |
| find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 | |
| rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. | |
| index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 | |
| rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. | |
| 编码类 | |
| encode(encoding=‘UTF-8’,errors=‘strict’) 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace | |
| bytes.decode(encoding=“utf-8”, errors=“strict”) Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
print("AbcDEF小明123".center(13,"P"))
输出PAbcDEF小明123P(原先11个字符,要用P填充成居中的13个字符,就是左右各加一个P)
print("AbcDEF小明123".center(12,"PP"))
会报错:The fill character must be exactly one character long
print('123'.center(2, '*')) # 123
print('123'.center(3, '*')) # 123
print('123'.center(4, '*')) # 奇数个字符时优先向右边补* # 123*
print('123'.center(5, '*')) # *123*
print('1234'.center(4, '*')) # 1234
print('1234'.center(5, '*')) # 偶数个字符时优先向左边补* # *1234
print('1234'.center(6, '*')) # *1234*
print('1234'.center(7, '*')) # **1234*
#除了count方法外,还有一个Counter的函数,需要引用collections这个Python内置模块,以字典的形式,输出每个字符串中出现的字符及其数量.一定注意,模块的c要小写,函数的C要大写,否则报错
form collections import Counter
s1="11558877669999"
print(Counter(s1))
结果是Counter({'9': 4, '1': 2, '5': 2, '8': 2, '7': 2, '6': 2})
str = "this is string example....wow!!!"
print (str.startswith( 'this' )) # 字符串是否以 this 开头
print (str.startswith( 'string', 8 )) # 从第九个字符开始的字符串是否以 string 开头
print (str.startswith( 'this', 2, 4 )) # 从第2个字符开始到第四个字符结束的字符串是否以 this 开头
str1 = "Runoob example....wow!!!"
str2 = "exam";
print (str1.find(str2))
print (str1.find(str2, 5))
print (str1.find(str2, 10))
#返回值分别是:7 7 -1
str1 = "this is really a string example....wow!!!"
str2 = "is"
print (str1.rfind(str2)) #5
print (str1.rfind(str2, 0, 10)) #5
print (str1.rfind(str2, 10, 0)) #-1
print (str1.find(str2)) #2
print (str1.find(str2, 0, 10)) #2
print (str1.find(str2, 10, 0)) #-1
isdigit()
True: Unicode数字,byte数字(单字节),全角数字(双字节)
False: 汉字数字,罗马数字,小数
Error: 无
isdecimal()
True: Unicode数字,全角数字(双字节)
False: 汉字数字,罗马数字,小数
Error: byte数字(单字节)
isnumeric()
True: Unicode 数字,全角数字(双字节),汉字数字
False: 小数,罗马数字
Error: byte数字(单字节)
isdecimal()和isdigit()的区别在于前者认为byte数字为true,而isdigit则会对byte数字报错。isdigit()和isnumeric()的区别在于前者会认为汉字中的数字为False,而isnuemeric()则认为汉字中的数字也是数字。
以下实例在Pyhon3中展示了使用 maketrans() 方法加 translate() 方法将所有元音字母转换为指定的数字,并删除指定字符:
intab = "aeiou"
outtab = "12345"
deltab = "thw"
trantab1 = str.maketrans(intab,outtab) # 创建字符映射转换表
trantab2 = str.maketrans(intab,outtab,deltab) #创建字符映射转换表,并删除指定字符
test = "this is string example....wow!!!"
print(test.translate(trantab1))
print(test.translate(trantab2))
以上实例输出结果如下:
th3s 3s str3ng 2x1mpl2....w4w!!!
3s 3s sr3ng 2x1mpl2....4!!!
s = input()
a = "〇一二三四五六七八九"
b = "0123456789"
for i in b:
n=s.replace(i,a[eval(i)])
print(n)
#注意 如果输入123 返回的还是123,因为n指向的内容还是最开始的s
n = input("")
s = "〇一二三四五六七八九"
for c in "0123456789":
n = n.replace(c, s[eval(c)])
print(n)
#注意 如果输入123,返回的是一二三
#str.join(sequence):用于将序列中的元素以指定的字符str连接生成一个新的字符串,注意,操作的对象是序列seq(其实手册的释义是可迭代对象,并不仅仅是序列,比如dic字典元素也可用,它不是序列,而是可迭代元素,输出的连接值是其key),返回的内容是字符串。必须要注意,如果序列中的内容不是字符类型,而是整数等类型,则返回报错,必须要把序列中的元素转成字符串。例如 print(" ".join([1,2,3]))的结果会报错,另外要注意,当连接的序列为set集合时,连接后的内容会随机打乱元素顺序。
print(" ".join(["1","2"])的结果是1 2
L = [1,2,3,4,5]
print(','.join(L))
以上写法会报错,TypeError: sequence item 0: expected str instance, int found
原因:list包含数字,不能直接转化成字符串
修改成 print(','.join(str(n) for n in L)) 就可以了
jn1="-"
jn2="------"
str='name'
jn1.join(str) #字符串也属于序列
'n-a-m-e'
jn2.join(str) #使用多字符连接序列
'n------a------m------e'
fruits={'apple','banana'}
jn1.join(fruits) #连接的序列是集合
'apple-banana'
animals=("pig","dog")
jn1.join(animals) #连接的序列是元祖
'pig-dog'
students={"name1":"joy","name2":"john","name3":"jerry"} #连接的序列是字典,会将所有key连接起来
jn1.join(students)
'name1-name2-name3'
关于字符串的 split()方法,如果分割成n个元素,然后用n个变量去接收,
那么每个变量的类型和元素的类型一致,并不是说变成了列表,
用一个变量去接受被分割的多个元素时,才是默认的列表来放
# head, tail = "AB-ABC-CABd-cb@".split('-', 1)
# print(head,tail)
# 输出结果是 AB ABC-CABd-cb@ 两个字符串格式
# A = "AB-ABC-CABd-cb@".split('-', 1)
# print(A)
# 输出结果是['AB', 'ABC-CABd-cb@']
#根据指定的字符,进行字符串分割的办法
a='7#6$5#12'
b=''
for i in range(len(a)):
if a[i] in '#$':
b=b+','+ a[i]+','
else:
b=b+a[i]
print(b)
结果是7,#,6,$,5,#,12
str.splitlines([keepends]):如果字符串里面有换行,则该方法返回一个包含各行作为元素的列表,一行的内容就是一个元素,keepends参数默认为False省略,表示不用输出换行符,如果为True,则换行符和改行内容作为一个元素。
'ab c\n\nde fg\rkl\r\n'.splitlines()
['ab c', '', 'de fg', 'kl']
'ab c\n\nde fg\rkl\r\n'.splitlines(True)
['ab c\n', '\n', 'de fg\r', 'kl\r\n']
str.partition(head,sep,tail):从左向右遇到分隔符把字符串分割成两部分,返回头、分割符、尾三部分的三元组。如果没有找到分割符,就返回头、尾两个空元素的三元组。
s1 = "I'm a good sutdent."
#以'good'为分割符,返回头、分割符、尾三部分。
s2 = s1.partition('good')
#没有找到分割符'abc',返回头、尾两个空元素的元组。
s3 = s1.partition('abc')
print(s2):("I'm a ", 'good', ' sutdent.')
print(s3):("I'm a good sutdent.", '', '')
9.字符串转列表
#字符转列表,通过list()函数 或者对字符串进行循环,然后每个元素输出到列表中实现
var='ABC'
print(list(var))
print([i for i in var])
#结果都是['A', 'B', 'C']
#列表转字符,通过 字符串的.join()方法实现,不能通过print(str(list))会报错
list=["A","B","C"]
print(",".join(list))
#结果是A,B,C
万分注意!!!如果列表里面包含数字,这样用会报错的,需要进行转str
L=[1,2,3,4]
print(''.join(str(n) for n in L))
#字符串转化为元组,使用 tuple() 函数
var='ABC'
print(tuple(var))
#结果是('A', 'B', 'C')
10.ASCII(ascii)码表
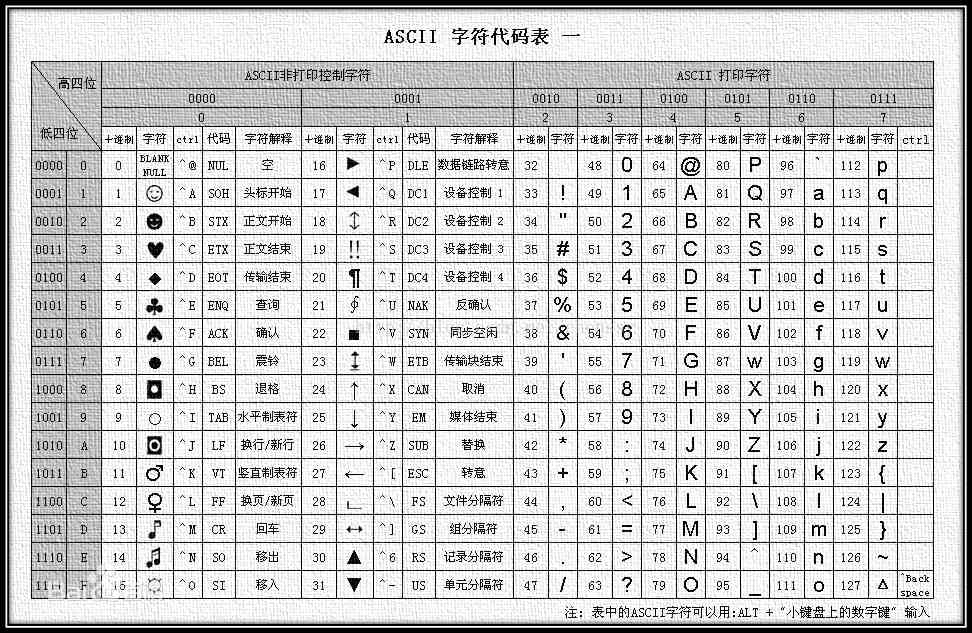
ascii表是一套电脑编码系统,例如一个字符a,你看到的是a,但在计算机中,一切都是以二进制存储的,ascii规定了每一个字符在计算机的二进制存储方式,a在计算机中的二进制存储方式是"01100001",转成成10进制数就是97。
你可能已经注意到,这个表里只有英文字母,没有咱们的汉字,我们中国也需要一套电脑编码系统,于是有了GBK,世界上这么多国家,都有各自的文字,都各自搞一套,不利于交流,于是有了unicode编码,包含了世界上几乎所有的文字
关于ASCII表,你需要掌握的是数字和英文字母的编码范围
- 数字0-9在ascii表里的编码范围是48~57
- 小写字母在ascii表里的编码范围是97~122
- 大写字母在ascii表里的编码范围是65~90
1. ASCII
在计算机里,一切都是用二进制存储的,也就是说,不管是处理字符还是图片还是视频,在计算机底层,都是处理的二进制数字0和1。比如 a 这个字母,在计算机里,用 0110 0001 这个8个比特(bit)来表示(把代表a的这个二进制转成10进制就是97),8个bit就是一个字节。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节最多能代表256个字符(8位数,每位数有0和1两种情况,总共有2的八次方种情况,也就是256种)。
所谓ascii,就是一个字符编码,它规定了英文中的各种字符在计算机里表示形式,或者说和二进制数的映射关系。ascii码可以表示128个字符(一个比特最多其实可以代表256种字符,但是ascii里只用了127个)与二进制之间的关系,ord()可以查看字符在ascii码表中对应的十进制数,char()可以返回十进制的数值在ascii码表中对应的字符。
en_str = 'a'
en_ascii = ord(en_str)
print(en_ascii, type(en_ascii))
print(chr(97))
输出结果
97 <class 'int'>
a
2. unicode
只要稍微一思考,就会发现一个严重的问题,由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,形成了ASCII编码表,包含大小写英文字母、数字和一些符号。
但是要处理中文显然一个字节是不够的,汉字远超256个,至少需要两个字节(2的16次方为65536,汉字虽然有接近十万个,但是常用的不足3000字,所以两个字节的6万多种可能已经能够覆盖汉字范围),而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
干脆,搞一个大点的字符集,把这个世界上所有的字符都进行编码,然后大家就用这套编码来处理文本,这就是unicode字符集。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
3. utf-8
utf-8解决了unicode编码存在的问题,它是一种变长的编码方式,UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
ascii_a = 'a'
ascii_a_utf8 = ascii_a.encode(encoding='utf-8')
print(ascii_a_utf8, len(ascii_a_utf8))
ch = '升'
ch_utf8 = ch.encode(encoding='utf-8')
print(ch_utf8, len(ch_utf8))
程序运行结果
b'a' 1
b'\xe5\x8d\x87' 3
UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
4. python3里的unicode
在python3中,字符串是以unicode编码的,当你想把一个字符串写入到磁盘上时,就必须指定用哪种编码方式进行存储,否则,就容易出错,比如下面的这段代码
with open('city', 'w') as f:
f.write('北京')
报的错误是
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
有了前面的内容做铺垫,你大概可以知道究竟发生了什么错误。
字符串采用的是unicode字符集,但是文件保存的时候,默认采用ascii编码,这就有问题了,ascii可以表示的范围太有限了,只有128个字符,可是汉字的unicode编码里很容易就出现大于128的字节,这就是错误发生的原因,解决这个问题,可以采取下面两种方法
4.1 指定utf-8编码
with open('city', 'w', encoding='utf-8') as f:
f.write('北京')
4.2 以二进制的形式写入文件
with open('city', 'wb') as f:
f.write('北京'.encode('utf-8'))
这种方法虽然也行,但并不常用,因为这需要每次写入都对字符串进行utf-8编码,不如第一种方法简单高效。
4.3 在 python文件开头指定编码
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:

如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:

二、练习题
1. 字符串方法练习题
在交互式解释器中完成下列题目
1. 将字符串 "abcd" 转成大写
2. 计算字符串 "cd" 在 字符串 "abcd"中出现的位置
3. 字符串 "a,b,c,d" ,请用逗号分割字符串,分割后的结果是什么类型的?
4. "{name}喜欢{fruit}".format(name="李雷") 执行会出错,请修改代码让其正确执行
5. string = "Python is good", 请将字符串里的Python替换成 python,并输出替换后的结果
6. 有一个字符串 string = "python修炼第一期.html",请写程序从这个字符串里获得.html前面的部分,要用尽可能多的方式来做这个事情
7. 如何获取字符串的长度?
8. "this is a book",请将字符串里的book替换成apple
9. "this is a book", 请用程序判断该字符串是否以this开头
10. "this is a book", 请用程序判断该字符串是否以apple结尾
11. "This IS a book", 请将字符串里的大写字符转成小写字符
12. "This IS a book", 请将字符串里的小写字符,转成大写字符
13. "this is a book\n", 字符串的末尾有一个回车符,请将其删除
答案如下
1. "abcd".upper()
2. "abcd".find('cd')
3. "a,b,c,d".split(',')
4. "{name}喜欢{fruit}".format(name="李雷", fruit='苹果')
5. string.replace('Python', 'python')
6. string[0:string.find('.html')] 或者string[0:-5]
7. 使用len函数
8. "this is a book".replace('book', 'apple')
9. "this is a book".startswith('this')
10. "this is a book".endswith('apple')
11. "This IS a book".lower()
12. "This IS a book".upper()
13. "this is a book\n".strip()
这里只对其中2个题目讲解
第4小题的程序直接运行会报错,因为字符串里面有两个需要替换的位置,而format方法里只传入了一个参数,显然是不够
第13小题,strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
2. 逻辑推理练习
不用解释器执行代码,直接说出下面代码的执行结果
string = "Python is good"
1. string[1:20]
2. string[20]
3. string[3:-4]
4. string[-10:-3]
5. string.lower()
6. string.replace("o", "0")
7. string.startswith('python')
8. string.split()
9. len(string)
10. string[30]
11. string.replace(" ", '')
答案如下
1. 'ython is good'
2. 报错
3. 'hon is '
4. 'on is g'
5. 'python is good'
6. 'Pyth0n is g00d'
7. False
8. ['Python', 'is', 'good']
9. 14
10. 报错
11. 'Pythonisgood'
第2题和第10题都报错,是因为超出了索引范围,字符串长度为14,你去20和30的位置取值,当然会报错
关于切片操作,只需要知道从哪里开始到哪里结束就一定能推导出答案,以string[3:-4]为例,3是开始的位置,-4是结束的位置,但这个范围是左闭右开的,从3开始没错,但不会到-4,而是到-5,更前面的一个位置,python支持负数索引,或者说是反向索引,从右向左从-1开始逐渐减小。
第一题中,做切片的时候是从1开始,到20结束,即便是右开,直到19,也仍然超出了索引范围,为什么不报错呢,这就是语言设计者自己的想法了,切片时,不论是开始位置还是结束位置,超出索引范围都不会报错。